拿去年高校战疫分享赛的一道kernel pwn题作为小白鼠,尝试多种内核利用方法,也踩了不少坑。不过还是学到了不少东西。
相关知识
Double Fetch
Double Fetch从漏洞原理上来说,属于条件竞争(race condition)的漏洞,是一种内核态与用户态之间的数据访问竞争。
借用CTF Wiki里的一张图: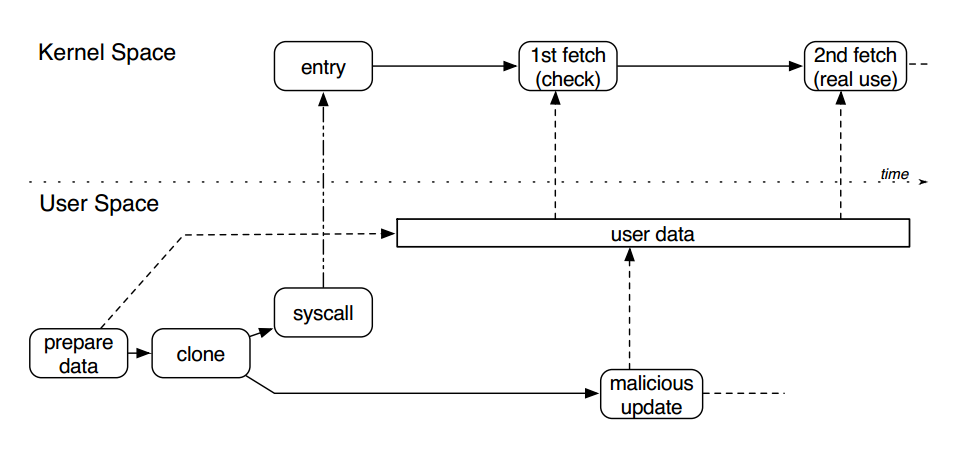
通俗地来讲,就是在kernel中,可能存在对一个user data进行两次访问的情况,而且第一次为检查,第二次才是真正的使用。那么在检查和使用两者之间,存在着时间窗口,使得user data可能在期间被修改,也就是说被检查的值和被使用的值前后不一致,从而导致检查无效而被绕过。
SLAB_FREELIST_HARDENED
SLAB_FREELIAT_HARDENED是一种内核保护机制,虽然它并不常见。但是要做这道题,(或许也可以不需要知道)了解一下它也很有好处。
在这个保护机制中,kmem_cache增加了一个unsigned long类型的变量random:
1 | struct kmem_cache { |
同时在kmem_cache_open中,random进行了初始化:
1 | static int kmem_cache_open(struct kmem_cache *s, slab_flags_t flags) |
这里有一个奇怪的点就是,这个s->random在实际调试过程中发现,并不是一个随机值,而是固定不变的,即使内核重启多次。至于具体原因得了解一下get_random_long的实现,先埋个坑。
重点我们关注在:
set_freepointer:这里引入一个1
2
3
4
5
6
7
8
9
10static inline void set_freepointer(struct kmem_cache *s, void *object, void *fp)
{
unsigned long freeptr_addr = (unsigned long)object + s->offset;
BUG_ON(object == fp); /* naive detection of double free or corruption */
*(void **)freeptr_addr = freelist_ptr(s, fp, freeptr_addr);
}BUG_ON(object == fp);的逻辑,就是说当前被free的object不能等于freelist的第一个object,如果对glibc的ptmalloc中的fastbin实现有了解的话,其实等同于fastbin对double free的检查逻辑。
检查通过后,通过调用freelist_ptr设置object的fd。freelist_ptr:可以看到,存放的fd的值是要经过1
2
3
4
5
6
7
8
9static inline void *freelist_ptr(const struct kmem_cache *s, void *ptr,
unsigned long ptr_addr)
{
return (void *)((unsigned long)ptr ^ s->random ^ ptr_addr);
return ptr;
}ptr ^ s->random ^ ptr_addr计算的,简单来说,就是将current_free_object ^ next_free_object ^ kmem_cache->random计算出来当作fd储存。get_freepointer:取1
2
3
4
5
6
7
8
9
10
11static inline void *get_freepointer(struct kmem_cache *s, void *object)
{
return freelist_dereference(s, object + s->offset);
}
static inline void *freelist_dereference(const struct kmem_cache *s,
void *ptr_addr)
{
return freelist_ptr(s, (void *)*(unsigned long *)(ptr_addr),
(unsigned long)ptr_addr);
}next_free_object的时候,也是做同样的异或操作。
了解了这些函数,我们也不难发现,对fd指针的加密确实给利用带来了不小难度,但是也并非毫无破绽。总的来说,我们无法轻易做到通过覆盖fd来实现任意地址读写,也无法轻易通过读取fd来获取到object的地址。
解题
题目分析
老规矩,看开的保护:
1 | !/bin/bash |
只开了smep。
分析一下noob.ko,常规的菜单,ioctl提供四个功能:
1 | __int64 __fastcall sub_436(__int64 a1, unsigned int a2, __int64 a3) |
分别是add_note,delete_note,edit_note和show_note。
其中:
add_note:这里可以发现,不管是做检查1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17__int64 __fastcall sub_48(unsigned __int64 *a1)
{
unsigned __int64 v2; // [rsp+10h] [rbp-18h]
__int64 v3; // [rsp+18h] [rbp-10h]
v2 = *a1;
if ( a1[2] > 0x70 || a1[2] <= 0x1F )
return -1LL;
if ( v2 > 0x1F || pool[v2].ptr )
return -1LL;
v3 = _kmalloc(a1[2], 0x14000C0LL);
if ( !v3 )
return -1LL;
pool[v2].ptr = v3;
pool[v2].size = a1[2];
return 0LL;
}a1[2] > 0x70 || a1[2] <= 0x1F还是作为size进行_kmalloc(a1[2], 0x14000C0LL);,还是存放在全局的数组中pool[v2].size = a1[2];,都是直接地访问用户空间的内容。
再加上其实startvm.sh中只开了smep而没有开smap,就铁定存在double fetch了。delete_note:这里显然是一个UAF,1
2
3
4
5
6
7
8
9
10
11
12__int64 __fastcall sub_121(_QWORD *a1)
{
__int64 v2; // [rsp+10h] [rbp-8h]
v2 = pool[*a1].ptr;
if ( *a1 > 0x1FuLL )
return -1LL;
if ( !v2 )
return -1LL;
kfree(v2);
return 0LL;
}kfree之后没有将全局数组中的相应ptr置0。show_note:只是简单地将1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19__int64 __fastcall sub_185(__int64 *a1)
{
__int64 v2; // [rsp+10h] [rbp-48h]
unsigned __int64 v3; // [rsp+18h] [rbp-40h]
__int64 v4; // [rsp+20h] [rbp-38h]
__int64 v5; // [rsp+28h] [rbp-30h]
v2 = *a1;
v3 = a1[2];
if ( (unsigned __int64)*a1 > 0x1F )
return -1LL;
if ( !pool[v2].ptr || v3 > pool[v2].size )
return -1LL;
v4 = a1[1];
v5 = pool[v2].ptr;
_check_object_size(pool[v2].ptr, v3, 1LL);
copy_to_user(v4, v5, v3);
return 0LL;
}pool[v2].ptr中的内容复制到用户空间中,可以注意到和add_note中明显不同的是,这里首先把a1[2]的值复制给内核的局部变量v3,之后都是对v3的操作,显然不会有double fetch的问题。edit_note:将用户空间中的内容复制到1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19__int64 __fastcall sub_2DD(__int64 *a1)
{
__int64 v2; // [rsp+10h] [rbp-48h]
unsigned __int64 v3; // [rsp+18h] [rbp-40h]
__int64 v4; // [rsp+20h] [rbp-38h]
__int64 v5; // [rsp+28h] [rbp-30h]
v2 = *a1;
v3 = a1[2];
if ( (unsigned __int64)*a1 > 0x1F )
return -1LL;
if ( !pool[v2].ptr || v3 > pool[v2].size )
return -1LL;
v4 = pool[v2].ptr;
v5 = a1[1];
_check_object_size(pool[v2].ptr, v3, 0LL);
copy_from_user(v4, v5, v3);
return 0LL;
}pool[v2].ptr中,其实这里也存在一个double fecth的问题,即v2 = *a1;赋值先做,然后再检查(unsigned __int64)*a1 > 0x1F,最后再用v2作为下标取ptr地址。
利用思路
这道题虽然存在double fecth的漏洞,但是可以用也可以不同,仅仅利用一个UAF同样可以完成提权。
double fetch方法
double fetch的方法,就是绕过add_note中对a1[2]也就是size的检查,实现对任意size大小的slub object进行UAF的利用。
最简单的做法,就是利用UAF,控制一个size = 0x2e0(也就是题目所给环境下cred结构体的大小)的object。之前我们有在babydriver这道题中提到,进行fork操作的时候,内核会分配一个cred结构题储存子进程的信息,控制一个同样size的object,然后修改cred中的uid,就可以完成提权。
这里引入第一个坑点:
在利用此方法进行提权的过程中,发现成功率为0,经过马哥的指点和调试,再结合网上的搜到的资料,发现在新版本的内核中,这种方法已经无效了。
原因在于,新版本内核中采用了cred_jar这个新的kmem_cache,与kmalloc使用的kmalloc-xx是隔离开的。
2
3
4
5
6
>{
/* allocate a slab in which we can store credentials */
cred_jar = kmem_cache_create("cred_jar", sizeof(struct >cred), 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC|SLAB_ACCOUNT, NULL);
>}如果需要刨根问底的话,可以对源码进行调试,按照以下调用路径:
会发现
cred_jar与普通的kmalloc-xx隔离的证据根本在于,进行find_mergeable返回值为0,也就是说cred_jar与kmalloc-xx是unmergeable的。
虽然在搜相关writeup的过程中,还是有搜到以这种方式写的exp,对此我表示怀疑,建议自行验证。
所以需要寻找另一条路,即可以同样仿照babydriver这题的rop做法,去劫持tty_struct,一大堆指针可以用来劫持控制流,然后做rop,提权,这里就不赘述了。
单纯的UAF方法
何为单纯的UAF做法?在本题中,既然在不考虑double fetch的前提下,只能做到对0x20-0x80的object进行UAF利用,那么我们就可以只在这个范围内,达到提权的目的。
这里引入一个结构体:
1 | struct seq_operations { |
存在四个函数指针,简直不要太好用;抛开这题不谈,其他题目中,用这个结构体来进行leak或者劫持pc,简直不能再方便。
首先了解一下这个seq_operations存在的意义是什么,什么时候会存在:
因为对proc文件系统进行读取的时候,限制了一次最多读一页,如果超过那么只能多次读取,这样就会增加读取次数从而增加系统调用的次数,影响了效率。所以出现了seq_file的序列文件出现,该功能使得对于读取大文件更加容易。
至于其中更深层次的细节,我这里就不赘述了,总而言之,试图读取proc文件系统中的文件时,会创建一个seq_file结构体,作为这个结构体成员的seq_operations也相应产生。
在打开一个序列文件的时候会调用seq_open,之后读取文件内容时,seq_operations的执行顺序为:
1 | start() ==> next() ==> show() ==> ... ==> next() ==> show() ==> stop(); |
也就是说,会先调用start,然后执行show,接下来判断next是否为空,若非空继续show,若空则stop。
于是,从利用的角度来讲,如果打开一个proc文件,比如/proc/self/stat,然后控制seq_opeartions->start为xchg eax, esp; ret;类似的栈迁移gadget,再进行后续的rop提权即可。
这里引入第二个坑点:
如果你尝试通过一个UAF object达到对
seq_operations的控制,你会怀疑这个结构体是否真实存在。
事实是,在编写exp并且调试的过程中发现,打开一个proc文件之后,总是第二个0x20的object被分配给seq_operations使用,但是我并没有深究第一个是被谁申请的,也并不清楚这在所有内核版本中是否是通用的情况。
而最保险的方法就是,多准备几个UAF的object,在分配了seq_operations之后,打印出第一个成员也就是start的地址进行验证。
这样exp就非常简单了,如下:
1 |
|
修改内核中的全局变量
我们通常会想,如果能得到内核任意地址读写的权限,怎么做才能最快最好地提权,或者说以root权限执行任意命令。实际上,最为直接也可能是最为高效的方法,就是找全局变量下手,事实上某些全局变量一旦被劫持,确实可以达到极其强大的效果。
首先照样从这道题目出发,我们首先要得到一个任意地址读写的能力,看似有了UAF,以及没有开kaslr保护,这会很容易。然而,注意到内核是开了SLAB_FREELIST_HARDENED的保护,并且无kaslr并不代表每次拿到的object地址也是可预测的。
首先来干件大事,把random算出来,看似不知道object的地址是没法准确算出random的,但是实际上并非如此(虽然这里发现random貌似都对不起这个名字,因为在我的环境下,它保持一个常值不变),即使它真的”random”,我们也能算出来。
考虑以下三种freelist的组织情况:
1 | freelist: |
那么将上述三个值进行异或,我们就能得到random:
1 | (random ^ &pool[1] ^ &pool[0]) ^ (random ^ &pool[2] ^ &pool[0]) ^ (random ^ &pool[1] ^ &pool[2]) = random; |
遗憾的是,得到random并不代表我们能算到object的地址,但是既然这是一个nokaslr的内核,就有nokaslr的做法。
调试过程中我们注意到,object的地址高5 bytes保持不变,且符合0xffff880005000000 - 0xffff880007000000的范围,只要想办法爆破出任意一个object的低3 bytes,我们就能顺利地任意地址读写了。
而我的方法就是,既然我计算出了random,也知道高5 bytes相对稳定不变,那么只要控制fd = random ^ 0xffff880000000000,那么在计算next_free_object的地址的时候,得到random ^ (random ^ 0xffff880000000000) ^ 0xffff88000xxxxxxx) = 0x000000000xxxxxxx),这显然落在用户空间内了。
只要相应地在用户空间内mmap大小为0x2000000内存,就可以成功kmalloc到用户空间,这个时候随意写入一个标志值,然后再在这块mmap区域进行搜索,定位到地地址就是目标object的低4 bytes,这样,我们就获得一个object的地址。
这里再引入一个坑点:
通常情况下,不考虑HARDENED的情况,我们劫持
object->fd指向任意地址,就能kmalloc到目标区域,达到任意地址读写的目的,虽然后续可能发生crash,但一般来说都是kernel内部发生的一些未预期的kmalloc试图从崩坏的freelist获取object。
然而在本题中,即使将object->fd加密并劫持,也极易crash,甚至在第一次kmalloc就crash,也就是说,根本无法正常得到目标地址区域的内存。
这里有两个原因:
一个是因为fd的加密,导致指向的目标地址(伪造的object)的fd经过解密之后不可能(在没有伪造数据的前提下)是0,即freelist并不会把它当作最后一个object。
还有一个原因,也是最重要的,在IDA反编译的代码中发现,kmalloc中的prefetch行为发生了微妙的变化,即从:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
{
...
do
{
v5 = __readgsqword((unsigned int)*v4 + 8);
v6 = __readgsqword(0xF138u) + *v4;
v7 = *(__int64 **)v6;
if ( !*(_QWORD *)(v6 + 16) || !v7 )
{
v15 = v4;
v13 = sub_FFFFFFFF81242240(v4, (unsigned int)a2, 0xFFFFFFFFLL, retaddr);
v7 = (__int64 *)v13;
v4 = v15;
if ( !(a2 & 0x8000) || !v13 )
return (__int64)v7;
LABEL_16:
sub_FFFFFFFF81987700(v7, 0, *((int *)v4 + 7));
return (__int64)v7;
}
v8 = v4[40] ^ *(__int64 *)((char *)v7 + *((int *)v4 + 8)) ^ ((unsigned > __int64)v7 + *((int *)v4 + 8));
}
while ( !(unsigned __int8)sub_FFFFFFFF81984E70(*v4, *v4, v5, v5 + 1) );
if ( v9 != v10 )
{
_RBX = v4[40] ^ *(_QWORD *)(*((int *)v4 + 8) + v8) ^ (*((int *)v4 + 8) + v8);
__asm { prefetcht0 byte ptr [rbx] } // ========== here ========== //
}
...
}变化为:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
{
if ( _s && !v4 )
{
while ( 1 )
{
slab_offset = __readgsqword((unsigned int)*_s + 8);
obj = *(_QWORD *)(__readgsqword(0xF138u) + *_s);
if ( !obj )
break;
_RBX = *(_QWORD *)(obj + *((unsigned int *)_s + 8));
if ( (unsigned __int8)this_cpu_cmpxchg16b_emu(*_s, *_s, slab_offset, >> b_offset + 1) )
{
_RAX = *((unsigned int *)_s + 8);
__asm { prefetcht0 byte ptr [rbx+rax] } // ========== here ========== //
if ( !(flags & 0x8000) )
return _ret_obj;
return _memset(_ret_obj, 0, *((unsigned int *)_s + 7));
}
}
...
}
...
}如果抛开异或操作不看的话,可以看出,虽然两者都对
next_next_free_object进行了prefetch的操作,但不同之处在于,一个是先计算而另一个不是。看似影响不大实则似乎引入了一个问题,就是考虑到伪造的object在这个代码环境下是作为free_object存在的,其next_free_object是一个非法地址,如果不去访问其中的内容或者只是在prefetch中访问是不会带来crash问题的;但是如果访问了其中内容即访问了非法地址,crash就不难理解了。
所以在调试的过程中,这个问题引发的crash让我怀疑人生,这里同样需要绕过。
所以我的解决方案是,内核搞不定的,全都搞到用户空间里。
即可以伪造一个object1,使其落在用户空间内(地址为random >> 32),且可以通过计算使得在地址偏移4 bytes得时候,伪造新的object2落在pool[idx] - 4的位置处,使得其本身地址满足形式random >> 32 << 32,从而使得random ^ (random >> 32 << 32)继续落在用户空间内,这样就可以通过在用户空间内伪造fd,使得next_next_free_object为0,成功bypass。
这样下来,我们才算完成了通过上述的object1完成任意地址读写的能力。
由于我们的攻击方法基于修改内核空间中的全局变量,这里给出两个,分别是:
modprobe_path:原值为”/sbin/modprobe”,一条触发路径是在执行某未知格式的文件时,依次调用到call_modprobe,作用是以root的权限执行modprobe_path指向的路径。如果能够劫持为我们的恶意脚本,那么就能实现以root权限执行任意命令。poweroff_cmd:原值为”/sbin/poweroff”,一条触发路径是通过orderly_poweroff调用,同样是root权限执行。稍显麻烦的地方在于,需要劫持控制流到orderly_poweroff执行。- 此外还有许多其他可利用的全局变量,但作用和目的大多类似,这里不再列举,可自行搜索。
如果利用orderly_poweroff的方法,由于需要劫持控制流,如果网上搜索的话,会经常看见一个叫做”Hijack Prctl的方法。
具体地来说就是如果在用户态调用prctl`系统调用,会执行以下路径:
1 | SYSCALL_DEFINE5(prctl, int, option, unsigned long, arg2, unsigned long, arg3, |
所以只要劫持hp->hook,然后调用prctl(...)就可以劫持控制流了。
这里再来一个坑点:
利用任意读写改
hp->hook的时候,发现竟然直接crash了,而且正是写入的时候crash了。
如果查看一下这部分hook的权限,就能发现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
LSM_HOOK_INIT(capable, cap_capable),
LSM_HOOK_INIT(settime, cap_settime),
LSM_HOOK_INIT(ptrace_access_check, cap_ptrace_access_check),
LSM_HOOK_INIT(ptrace_traceme, cap_ptrace_traceme),
LSM_HOOK_INIT(capget, cap_capget),
LSM_HOOK_INIT(capset, cap_capset),
LSM_HOOK_INIT(bprm_set_creds, cap_bprm_set_creds),
LSM_HOOK_INIT(inode_need_killpriv, cap_inode_need_killpriv),
LSM_HOOK_INIT(inode_killpriv, cap_inode_killpriv),
LSM_HOOK_INIT(inode_getsecurity, cap_inode_getsecurity),
LSM_HOOK_INIT(mmap_addr, cap_mmap_addr),
LSM_HOOK_INIT(mmap_file, cap_mmap_file),
LSM_HOOK_INIT(task_fix_setuid, cap_task_fix_setuid),
LSM_HOOK_INIT(task_prctl, cap_task_prctl),
LSM_HOOK_INIT(task_setscheduler, cap_task_setscheduler),
LSM_HOOK_INIT(task_setioprio, cap_task_setioprio),
LSM_HOOK_INIT(task_setnice, cap_task_setnice),
LSM_HOOK_INIT(vm_enough_memory, cap_vm_enough_memory),
};这个
__lsm_ro_after_init存在大问题,如果把提取出来的vmlinux放到IDA中分析,也能发现这个hp->hook它在.rodata段中,根本没法改。
那为什么这方法这么流行?
后面找了个4.4的内核,才发现:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
LSM_HOOK_INIT(capable, cap_capable),
LSM_HOOK_INIT(settime, cap_settime),
LSM_HOOK_INIT(ptrace_access_check, cap_ptrace_access_check),
LSM_HOOK_INIT(ptrace_traceme, cap_ptrace_traceme),
LSM_HOOK_INIT(capget, cap_capget),
LSM_HOOK_INIT(capset, cap_capset),
LSM_HOOK_INIT(bprm_set_creds, cap_bprm_set_creds),
LSM_HOOK_INIT(bprm_secureexec, cap_bprm_secureexec),
LSM_HOOK_INIT(inode_need_killpriv, cap_inode_need_killpriv),
LSM_HOOK_INIT(inode_killpriv, cap_inode_killpriv),
LSM_HOOK_INIT(mmap_addr, cap_mmap_addr),
LSM_HOOK_INIT(mmap_file, cap_mmap_file),
LSM_HOOK_INIT(task_fix_setuid, cap_task_fix_setuid),
LSM_HOOK_INIT(task_prctl, cap_task_prctl),
LSM_HOOK_INIT(task_setscheduler, cap_task_setscheduler),
LSM_HOOK_INIT(task_setioprio, cap_task_setioprio),
LSM_HOOK_INIT(task_setnice, cap_task_setnice),
LSM_HOOK_INIT(vm_enough_memory, cap_vm_enough_memory),
};这才发现没有
__lsm_ro_after_init,所以是可以改的。
那么意味着新版内核这个方法应该不再适用了。
在本题中,我们通过任意地址写,可以修改modprobe_path,然后执行错误格式文件触发任意命令执行;也可以修改poweroff_cmd,然后再次利用seq_operations->start为orderly_poweroff来触发。
最后一个坑;
实现对全局变量的修改之后,由于我们在用户空间布置了一块内存,如果不同时把这个用户空间伪造的object给分配出来的话,极大的概率会crash。
这是由于内核中跑了两个线程,如果另一个线程在kmalloc的时候尝试分配这个伪造的object,会因为在这个线程里不存在我们exp线程中mmap出来的内存,而触发page fault。
所以只要在exp中继续把这个用户空间伪造的object给拿掉,后续的kmalloc就会从新的page里拿而不会导致crash了。
提供以下exp:
1 |
|
bonus
这题貌似环境没有配置好,导致各种非预期满天飞,抛开直接strings的和直接从给的本地环境中直接读到的不谈,这里有两个比较有意思的,都是因为所有文件的owner都是pwn而不是root:
rm /sbin/poweroff然后直接exit,由于启动脚本etc/init.d/rcS里:退出最后会执行1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20!/bin/sh
echo "Welcome :)"
mount -t proc none /proc
mount -t devtmpfs none /dev
mkdir /dev/pts
mount /dev/pts
insmod /home/pwn/noob.ko
chmod 666 /dev/noob
echo 1 > /proc/sys/kernel/dmesg_restrict
echo 1 > /proc/sys/kernel/kptr_restrict
cd /home/pwn
setsid /bin/cttyhack setuidgid 1000 sh
umount /proc
poweroff -fpoweroff,如果没找到/sbin/poweroff自然报错执行不了,这个时候就会得到root权限。- 同样地
rm /bin/umount,然后自己写一个”/bin/sh”仍里面,exit同样会执行umount命令,从而直接拿到root权限。
不过看看就好,一般来说不会出现这样的失误。